へぼい日記
YAPC::Kyoto 2023参加してきました
- 2023/3/24 金曜日 16:25:51
- perl
YAPC::Kyoto 2023に参加してきました。YAPCにはYAPC::Asia Tokyo 2015以来の参加なので、なんと8年ぶり(!)。
トーク応募もせずに京都までいくのはどうなんだろうとも思ったのですが、実は京都に一度も訪問したことがなかったため家族も呼び寄せ京都旅行も兼ねて行ってきました。
聞いた発表からいくつか感想
2023年春のPerl
Perl最新情報ぜんぜん追えてないマンとしてはすごくためになりました。
売上と開発環境を同時に改善するために既存のPerl Web アプリケーションをどのようにリプレイスするか
Perlでつくられた古いサービスをどうやって持続的に運用していくのか…。おそらくYAPCに参加されている方の多くに共通する悩みですよね。言語としてはPerlを維持しつつモダンにしていくという選択とその方法とても参考になりました。
ORM – Object-relational mapping
Tengだ!
テーブル名が文字列指定だと静的解析がしづらいからRepository層を作るというのはなるほどな〜となりました。
デプロイ今昔物語 〜CGIからサーバーレスまで〜
2000年ごろのCGI時代からPerlの世界にはいった自分としては懐かしい思いもありつつ眺めていました。
push型deployのデメリットとして、オートスケール構成にしている場合にdeployのタイミングでスケールが起こった場合を挙げられていたのは、意識したことがなかったので勉強になりました。
DNS権威サービスへのDDoSとハイパフォーマンスなベンチマーカ
ベンチマーカーのチューニングをしていく手順がすごかったです(小並感
nekokakさんのゲストトーク
nekokakさんはDBIx::SkinnyやTengの開発で十数年前にはIRCでよくやりとりをしていたのですが、バリバリのPerlハッカーというイメージでした。その後自分も(おそらく)nekokakさんもCPANモジュールのOSS開発を活発に行わなくなりどうされているのかな〜と思っていた期間のミッシングピースがすこし知れたような思いがしました。バリバリのPerlハッカーから経営にも参画するCTOになられるというのは、エンジニアの一つのモデルケースとして素晴らしいですね。
onishiさんのキーノート
2000年代初期からPerlに触れている者としては”はてな”や”オン・ザ・エッジ”という会社には特別な思いがあるわけです。たとえば2002年にperl-oo MLでjkondoさんがデザインパターンをPerlで書くということを披露されているのをリアルタイムで見ていたりもしました。いまだにはてなに憧れはあるわけです。そんなはてな創業期から参加されいまは取締役 組織・基盤開発本部長として引っ張っておられる大西さんのはてなとご自身の歴史を振り返られたキーノートでした。自分もモブキャラと自認していることもあり、それじゃ駄目だと行動を変えていくという姿勢にとても感銘をうけました。YAPC2010のmiyagawaさんのキーノートに自分も感動していたのですが、遅くてもやらないよりマシ、いい言葉ですよね。
感想など
せっかく来たのだからトークはせずとも参加感を出そうということで、3回ほど質問はさせていただきました。良い質問とは言えなかったと思いますが、登壇者の方々には真摯に回答していただきました。ありがとうございます。
やはり、こういうカンファレンスに参加すると刺激をうけますね。YAPCでの登壇はYAPC::Asia Tokyo 2012で唯一やっているわけですが(11年前!)、いまさら自分がなにか話せることはあるのだろうかと思いつつ、次回の開催があればばトーク応募できるようにしたいと思いました。
開催者、ボランティアスタッフ、発表者の皆様お疲れさまでした&ありがとうございました。素晴らしいイベントでした。

#isucon12 参戦記録
- 15:16:02
- ISUCON
ISUCON11にはオンライン予選の参加申し込みの先着順申し込みに間に合わず、11回目にして不参加という事態になり、だいぶやる気をなくしていたのですが、奮い立たせてなんとかISUCON12には申し込みが間に合い、参加してきました。その結果をだいぶ遅くなりましたが記しておきます。
チーム名はいつもどおり山形組です。
予選
一般枠25位という結果で、ギリギリ中のギリギリで通過。
なにをやったのかあまり覚えてないのですが、gitログを見るとN+1退治、テナントDBの統合、請求金額など事前計算できるものをinitialize前事前実施などを行ったようです。
本戦
当初の発表ではfailという扱いだったのですが、その後再起動試験について見直しが行われ16位という結果でおわりました。
failじゃなかったのはよかったですが、下から数えたほうが早いスコアということで厳しい結果でした。
DBの水平分割はできていたのですが、他のボトルネックを確実に潰すということができていなかったのかなと思います。
感想
不参加により2年間の時が過ぎ情熱も薄れていたのですが、期せずして本戦にも進むことができ熱い思いを少し取り戻すことができました。(しばらくブログ書かないで何を言っているんだという感じもしますが)
運営の皆様、ありがとうございました。
来年もあればまた参加したいです。できれば本戦はオフラインで!

- コメント(閉): 0
- トラックバック(閉): 0
#isucon10 予選惨敗してきました
- 2020/9/13 日曜日 12:12:28
- ISUCON
今年もISUCON10に山形組として参加してきました。
結果はベストスコア(1400ぐらい)もボーダーに届かないまま、ギリギリまで修正をいれてfailで終了ということになりました。
できたこと
– nginxでbotに503
– app2台、db1台構成
– UPDATEのWHEREにstock > 0を追加してaffected rowsをみてbuyのFOR UPDATE外し
– recommendedを $w, $h, $dの昇順から2つとって(door_width >= %1 AND door_height >= %2) OR (door_height >= %2 AND door_width >= %1)に単純化
– nazotte検索をmysqlのPOINT型に変換してSPATIAL INDEXを貼ってクエリ一回で解決できるように
– 手当たり次第にindex
– index済みdumpデータを/initializeで読み込むように
– rangeId,priceId,widthIdみたいな検索をidで検索できるようにフィールド追加して変換
できなかったこと
– features検索にindexを効かせる施策。これは昇順sortしたidのカンマ区切り文字列にして完全一致検索にするものを実装したんだけどベンチ通らなくなってrollback。コードじゃなくてdumpデータがバグっていたのかも。
競技後気づいたこと
– CSV入稿時のbulk insert。普段の仕事では当たり前のようにやることなのに競技中は気づいてなかった。終わったあとに、ベンチの後半になると入稿のPOSTに時間がかかっていることに気づいて後悔
– ORDER BY `popularity` DESC , `id` ASC 対策。discord#random でほかの参加者の解法をみていてなるほどなぁ…と。popularityをマイナスにしてASCにしてしまうのとかすごいなと思いました。
今回は時間が足りてなかったというよりも競技中に気づけていなかったことが致命傷だったようで知識不足や認識力不足を感じましたし、まだまだ学ばないといけないことがあるなと。今あらためてDBのインデックスに関する基礎を学べる本を読むべきだと感じました。
運営のみなさま
今回もとても楽しませていただきました。(そしてとても悔しいです!)
来年またあれば参加したいです。ありがとうございました。

#isucon9 参戦記録
- 11:34:22
- ISUCON
去年もisucon9に参戦してたのだけど、いろいろいそがしくて何もブログをかけていなかったので一応簡単に記録として記事にしておくことにします。このあと今年のisucon10の記事も書きます。
予選
予選は14位で通過
– Perlを選択
– 無駄なAPI呼び出し排除
– N+1の解決
– FOR UDPATE外し
– campaign値の操作
– worker数調整
などなどである程度順調にスコアを伸ばしていった模様。(当時のコミットログより
本戦
isucon9回目の参加(本戦は7回目)にして初のfail終了。
競技中の最終コードはスコアがでていたので(まったく上位に絡めるスコアではなかったけど)再起動によるものだったのか不確定要素がなにかあったのか、よくわからないまま無気力になり記憶が途絶えてます。
1年ブログがかけなくて申し訳なかったのですが運営の皆様、ありがとうございました。

#isucon 8 本戦10位で負けてきました
- 2018/11/3 土曜日 21:28:22
- ISUCON
ISUCON8本戦に山形組でISUCON6以来の2年ぶりに参加してきました。結果は既報の通り学生チームである「最大の敵は時差」さんが優勝され、我々は10位という残念な結果となりました。(そういえば今回、本戦の結果の受賞チーム以外の公式発表が対参加者以外にないですね)
山形組の過去を振り返ると
ISUCON1、下から数えたほうが早い順位
ISUCON2、準優勝かつ特別賞
ISUCON3、予選総合3位、本選5位
ISUCON4、予選総合4位、本選10位
ISUCON5、予選落ち
ISUCON6、予選総合2位、本選10位
ISUCON7、予選落ち
ISUCON8、予選総合15位、本選10位
とまあ、なぜか2年おきに本戦出場し10位になるということを繰り返しております。来年はジンクスを打ち破って2年連続で予選突破して本戦優勝を果たしたいです。
やったこと
- 選んだ言語はもちろんPerl
- 初期スコア: 1588
- 最初のお決まりの作業
- ただ、すべてがdocker上でうごいていて、よくわからん…となったので、とりあえずログをいつものようにとるためにnginxを剥がす
- ここで妙にはまって時間を消耗
- ここで妙にはまって時間を消耗
- 12:53 遅めの作戦会議。スプレッドシートに共有した作戦リストが以下。見積もり時間と担当を決めてそれぞれとりかかる。
– N+1の地道な解決
– はやくなったら、enable_shareをonにする
– ログ送信用のワーカーをつくり/bulk_send を実装
– static expires max
– isu4 の mysql を利用する
– appをisu2,3に並列稼働
– appをdockerからはがす
– app のプロセスの状況を見る
– cache関連 - 13:19 score:2560
SELECT * FROM trade ORDER BY id DESC
にLIMIT 1
追加 - 13:46 score:2756
ALTER TABLE `isucoin`.`trade` ADD COLUMN `created_at_sec` DATETIME(6) NULL AFTER `created_at`, ADD COLUMN `created_at_min` DATETIME(6) NULL AFTER `created_at_sec`, ADD COLUMN `created_at_hour` DATETIME(6) NULL AFTER `created_at_min`, ADD INDEX `idx_sec` (`created_at_sec` ASC), ADD INDEX `idx_min` (`created_at_min` ASC), ADD INDEX `idx_hour` (`created_at_hour` ASC); update trade set created_at_sec=STR_TO_DATE(DATE_FORMAT(created_at, '%Y-%m-%d %H:%i:%s'), '%Y-%m-%d %H:%i:%s'),created_at_min=STR_TO_DATE(DATE_FORMAT(created_at, '%Y-%m-%d %H:%i:00'), '%Y-%m-%d %H:%i:%s'),created_at_hour=STR_TO_DATE(DATE_FORMAT(created_at, '%Y-%m-%d %H:00:00'), '%Y-%m-%d %H:%i:%s');
結果意味なかったかもしれないけど、秒、分、時の切り捨てをあらかじめ行うように。 - 14:02 score:4351
Starletのworkerを5->15に - 14:13 score:4530
staticファイルをnginx serve/expires max - 15:00 score:4673 orders.userのN+1外し
- 15:24 score:4144 isu4のDB参照(2台構成へ)
- 15:47 score:4726 tradeのN+1外し
- 16:04 score:4904 isu2/isu3にround robin(4台構成へ)
- 17:34 score:8191 enable_shareを1/7(約14%)有効に
- 17:49 score:8389 enable_shareを 22% 有効に
- その後いろいろshare rateをいじるが最終提出は22%で、最終走行では score:9473 で10位
上記に書いてないこととして、テーブルのパーティショニングには気づいて、外すのを試したりしていたのですが、逆に大幅スコアダウンしたりしていてもとに戻したりしていました。後から考えてみると、チーム連携がうまくとれてなくて関係ない変更がまぎれていたのか、DBのウォームアップ的な問題だったのか…。
全体的にdocker絡みで操作にまごつくことが多くて、最初から予定していたbulk_sendの実装もできないほど時間が足りない状態に陥ってしまい、少ない残り時間をenable_shareのrate調整という本質的ではない作業に割いてしまっていました。肝心のtrade部分のチューニングは考える時間すらほとんどとってなかった状態でして、バックグラウンドにまわして直列化するなんてまったく考えついてもいなかったので、完敗ですね…。banの実装もやろうともしていなかったです。
感想戦
先週末、感想戦をやりきれるだけやりきってみました。そこでやったことはこちら。(細かくscoreとってないので大雑把ですが
- /send_bulkをbackgroundプロセスで実装
- score:11318 tradeをbackgroundで0.1秒おきに実行
- score:32245 chart_by_*をsettingsテーブルにcache
- score:40999 remove partition/bcrypt cost
- score:53800 5回連続ログイン失敗のban
- score:67402 isuconbank:commitを run_tradeからさらにbackground化してrun_tradeを早くまわすように
- score:74507 lowest/highestとかもcache
- score:113736 nginxのworker_rlimit_nofile 4096;
- score:137392 tradeのロジック最適化/settingsのプロセス内キャッシュ/isubank,isuloggerのhttp keepalive
- どこでやったかわすれたのですが
/etc/sysctl.conf
にnet.netfilter.nf_conntrack_max = 100000 net.nf_conntrack_max = 100000
を追記
といったところで、13万点超えでその時点での感想戦1位をとって満足してやめていたのですが、翌朝おきたら40万点超えの学生チームが現れており、ただ笑うしかなかったです。
感想
感想戦をやってみて改めて実感しましたが、いろいろなところにボトルネックが隠されており、総合力が試されるとてもよい問題でした。
毎度のことながら来年のことはまだ決まっていないと思いますが、開催されるようであれば、もちろん参加したいです。
出題を担当された、カヤックの方々、協力をされていたDeNAやその他の方々、運営のLINEのみなさまには感謝です。こんなに熱く楽しいイベントの開催を毎年維持されており本当にすごいことだと思います。ありがとうございました!

#isucon 8 予選15位で通過しました
- 2018/10/10 水曜日 21:05:09
- ISUCON
毎年でているISUCONに今年も山形組として参加してきました。
結果は総合15位ということで、ギリギリでしたが予選通過しました。第1回からずっと同じ2人チームで参加していて、本戦出場回数は6回(1, 2, 3, 4, 6, 8)になったみたいです。そろそろ本戦優勝したいです。
やったこと
- 事前準備は空レポジトリ作成と、情報共有と秘伝のタレのコピペ用のスプレッドシートの作成など
- 選んだ言語はもちろんPerl
- そろそろGoで挑戦しますか?というのを3年ぐらい言い続けて未着手
- 普段の仕事はPerlなので手に馴染んだ道具を使うということでいいと思っている
- 最初のおきまりの作業
- 初回ベンチ
- 初期コードのレポジトリコミット
- デプロイスクリプト用意
- アプリの挙動確認
- コードリーディング
- 作戦会議
- ここまでで2時間ほど
- 作戦会議
- 「あー、これはISUCON2再来な問題ですねぇ。」
- そのISUCON2のときに我々はアプリケーションを全部書き換えて、データをメモリにすべて乗せるという戦略をとって、2位という結果を残していた
- けど、ISUCON5の予選で惨敗してからはその戦略をきっぱりやめているので、今回も普通のチューニングを進めていくことに
- 予約情報のデータ量が多いので、高速化が進むと途中からデータストアプロセス(初期はMariaDB)のメモリに全データが乗らなくなるという、ISUCON2の我々の戦略に対するカウンターなのでは?という予測をたてる
- イベントIDで接続先DBを決定して、 3台または2台のDBで水平分散というのが最終形かなぁ(結局準備はすすめたけどやらず)
- というのを意識しつつ直近のボトルネックを改修していきましょうというスタート
- 「あー、これはISUCON2再来な問題ですねぇ。」
- ISUCON7のときのCache-Control: publicやISUCON4のときのCache-Control/Expiresの悔しい思いがあるのでキャッシュ関連を調査
- HTTPのreq/resヘッダーを未知のものも含め全てログ保存する自作のPSGI middlewareを用意して、ベンチ中の全ヘッダーをみれるように
- 同じことをやるmiddlewareがないので整理して公開してもよいかも
- 各種キャッシュ関連のレスポンスヘッダをいろいろと付与して、appにくるアクセスでは条件付きリクエストの類はまったく行われないことを確認
- HTTPのreq/resヘッダーを未知のものも含め全てログ保存する自作のPSGI middlewareを用意して、ベンチ中の全ヘッダーをみれるように
- 実際に行った改修
- 12:52 sheetsテーブルのインメモリ化
- 13:41 h2o -> nginx
- 14:14 座席の詳細いらないときにも内部的にはとってきているのを省略
- 15:22 残席数の取得を1SQLに。こういうSQL各所に書いた。
SELECT e.*, count(case when r.sheet_id between 1 and 50 then 1 else null end) as reserved_S, count(case when r.sheet_id between 51 and 200 then 1 else null end) as reserved_A, count(case when r.sheet_id between 201 and 500 then 1 else null end) as reserved_B, count(case when r.sheet_id between 501 and 10000 then 1 else null end) as reserved_C FROM events e left join reservations r on (r.event_id=e.id and r.canceled_at is null) WHERE e.id = ? group by e.id - 15:43
where public_fg=1
をPerlでやっているのをSQL化 - 15:43 reservationsにindex追加
KEY `event_id_and_sheet_id_idx` (`event_id`,`sheet_id`), KEY `event_id_cancel` (`event_id`,`canceled_at`)
- 16:05 get_event内でreservationsに全シート分の1000回クエリなげてるところを1回に
- この時点でスコアは 18,992 でベストスコアで3-4位あたり
- 16:13 isu1のオールインワン構成から isu1-web/app isu3-dbに(isu2はこのあと最後まで遊ばせることに…
- 16:55 いくつかのFOR UPDATE消し/ IFNULL(canceled_a, reserved_at)をmodified_at化
- 17:00 他チームのスコアが非公開になるタイミングで、スコア: 44,450でベストスコア2位で折り返し
- 17:24ごろ get_login_userの呼び出し抑制、FOR UPDATEの削除
- このあたりで、ベストスコアの 57,093
- event_sheetsテーブルを新設して、予約を
UPDATE event_sheets set reserved=1, hash=? where event_id=? and rank = ? and reserved=0 order by rand() limit 1
というSQLでやるというのをいれたけどスコアが下がり取り下げ - ~18:00 取り下げたけどその後スコアが安定せず、実行するたびに2万台~3万台をうろうろ
- 最終スコアをなんとか 39,677 にもっていき終了
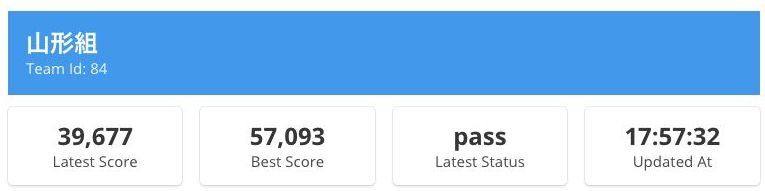
感想
最後スコアが安定しなかったのは、FOR UPDATE消したことも影響しトランザクションにミスがあったことが原因だというのは感想戦でわかりました。なので正直最後は運もあったなぁという感じはしています。
感想戦ではその後
– isu1-web/app isu2-app isu3-db の3台構成に
– event_sheetsの件を再投入
– 適切なトランザクション
で10万点までとれました。
予選での複数台構成、コードのボリューム、ベンチの快適さ、運営全体のストレスのなさ、すばらしい予選になっていたと思います。(通過したからというバイアスもありますが)
karupaneruraさんをはじめ出題担当されたDeNAの方々、カヤックさんはじめ協力されていた方々、LINEの運営を担当されている方々には感謝です。
ということで、何はともあれ、本戦にまた参加できることになり嬉しいです。
今度こそ優勝だ!

#isucon 7 予選敗退しました
- 2017/10/29 日曜日 13:10:52
- ISUCON
毎年でているISUCONに今年も山形組として参加してきました。
結果は71位ということで、つまり惨敗してきました。
やったこと
選んだ言語はPerlでした。やれたことは、
- 全3台でnginx/app 1台でDB構成に
- index貼り
- (中途半端だけど)クエリチューニング
- 既存画像のファイル化と全3台への配置
- 新規画像のファイル化と他2台への配置
- /fetchだけfeersumにしてプロセスが詰まらないように
- /fetchをsleep 9秒にして新規投稿があったらすぐに返すように
で、Bestスコア 81,227, 最終スコア 50,956
やれなかったこと
競技後のネタバラシで気づいたことは
- Cache-Control: public
- 画像ファイルの更新時間あわせ
後者は完全なる自分のミスで、競技中にEtagが揃ってるかということは気にして確認したのですが、たまたま確認したファイルは揃っていた(か確認ミスしていた)ため、強制的に揃える仕組みで配置していなかったことに気づかず終わりました。
画像をファイル化してからボトルネックが帯域だと分かっているのに4時間ほど何もできないままでした。
本戦出場されているみなさんのblogをみていると、リクエストHTTPヘッダを冷静に分析するとか、Cache-Controlの仕様を読み直すとかやれることは確実にあったので、実力不足を痛感しました。
Cache-Control: public
これつけなくても普通はキャッシュするジャンスカともやっとしていたのですがRailsのアセットパイプラインのドキュメントだとpublicをつけることが例示されていて、実際にGCPのCDNでは“Cache-Control: public ヘッダーがある。”というのがキャッシュの条件として明示されていることも確認できました。
静的ファイルのCache-Control: publicは今後は実務でもつけていこうという知見を持ち帰ることができました。
来年
人任せなので希望でしかないですが、来年あったらまた参加したいです。
出題チームのKLab、主催のLINE、サーバー提供のSAKURA internetの皆様、本当にお疲れ様でした。本戦もよろしくお願いしますといえないのが非常に残念ですが、本戦の様子がレポートされるのも楽しみにしております。

#isucon 6 本戦10位で負けてきました
- 2016/10/30 日曜日 17:41:42
- ISUCON
ISUCON6本戦に山形組でISUCON4以来の2年ぶりに参加してきました。結果は既報の通り予選で1位だった「この技術部には問題がある!」チームさんが勢いそのままに優勝され、予選2位だった我々は本選では10位という残念な結果となりました。(予選の結果は本選には何も関係ありませんが)
山形組の過去を振り返ると
ISUCON1、下から数えたほうが早い順位
ISUCON2、準優勝かつ特別賞
ISUCON3、予選総合3位、本選5位
ISUCON4、予選総合4位、本選10位
ISUCON5、予選落ち
ISUCON6、予選総合2位、本選10位
とまあ、なんとも煮え切らない歴史になっており、せめてISUCON5で予選通過さえしてれば全部でてるんだと胸を張れた部分もあるんですが。
やったことなど
Docker( Compose)で Node.js, mysqld, App が起動されていて、かつNode.jsという特定の言語のアプリケーションが配布時は選択肢なく居座っているというのがいままでになく、Dockerはかろうじて遊びで触ってはいたけどNodeはチュートリアルすらやったことがないという状態で、これはやばい…というのが最初の印象。
で、いつものごとくAppはPerl実装に切り替え。
お絵かきをストリーミングで実装したアプリケーションってことで。お、ストリーミングは昔Plackの実装で遊んだことあるなー、必要になったらそのときのコード持ち出してやってみるかーと思ったものの結局できず。ストリーミングの部分、2秒以内であればPubSub的な実装でそれ以上はやくしてもスコアに直接は影響なかったようなんですが、mysqldへのポーリングがなくなって全体的にチューニングしやすくなったはずなので、やれなかったのは悔いが残るところ。
Dockerによる構成ついては、それ自体が勝敗を分けるパフォーマンス上のボトルネックになるわけがないと思ったので、当初はそのままでアプリケーションの改修をしていくことに。
ところがAppのコードの変更を反映する方法がわからず、イメージの削除をしてかなり時間のかかるbuildしなおしをする方法しか見いだせず…。これは開発上のボトルネックになるなと判断して、Appとmysqldについては外だしを行い、Node.jsはやったこともない環境構築で意味なくはまるのも怖かったのでそのまま。
フロントにNginxをたててTLS終端もそこで行いつつ、Node.jsをHTTPSからHTTPのサーバーに切り替え。
Node.jsのAPI-URLはNginxを一度経由するようにしてAPIをほかのサーバーに分散できるように。
全サーバーでAppを立ち上げてNginx経由で標準分散。
strokeとpointsの取得がN+1だったところを2回のクエリになるように調整。
C10kにはMonocerosやろってことで/api/stream専用のAppをMonocerosでたちあげ。(keep-aliveじゃなくて全プロセスがDBのポーリングしてるので意味なかったんだろうけど…)
あとは各プロセスのワーカー数の調整とmysqldのtoo many connection対策に腐心して終了。
ワーカー数の調整は/api/streamにめいっぱいふっとけばもっとスコアあがったのかもしれないなぁ…。
感想
構成に面喰いすぎて、普段やっている1時間後の戦略会議的なこともきちんと行えなかったし、全体的にふわっふわと場当たり的なことばかりしていて、よくある負けパターンに陥ってしまっていました。
ほかにもチームメイトとの連携など反省点はたくさんありますが、次回以降にそれを活かせるよう普段の仕事でも意識していければなと…。
過去のISUCONにそれなりにでている自分ですが、懇親会で周りを見渡してみると、参加者で一方的にでも顔を知っている人は優勝(経験)者の方とYappoさんのチームとあと何人かぐらいで、こうして普段接することのない人たちと競い合い、感想をぶつけあうことができるというのは本当に素晴らしいことだと思います。(あまり積極的に懇親するタイプではないですが…)
個人的な余談ですが、学生チームの中には自分の息子と同じ学年(高1)の方がいたそうで、そのチームにはなんとか勝ってたようなんですが、これはいよいよ大変なことになってきたぞと。
そして、はたしてISUCON7は開催されるのか…どこが出題するのか…。まだわかりませんが、開催されたらもちろんまた参加したいと思います。
予選・本選の出題者のみなさん、主催・共催をされた企業の方々、今年もめいいっぱい楽しませていただきました。ありがとうございました!

#isucon 6 予選二位で通過しました
- 2016/9/24 土曜日 18:14:08
- ISUCON
去年は初めて予選敗退し悔しい思いをしたISUCONに今年も山形組として参加してきました。
結果は総合二位で本戦出場を決めました。やった!
事前準備
前日にメンバーで作戦会議をして、「フルスクラッチ書き換えはやらない」という方針で大決定。過去フルスクラッチ書き換えでそこそこの結果を残してきた我がチームですが、去年の予選で手痛い失敗をしたのもあり今年は確実に予選を突破しようということで封印することになりました。
過去問を改めて解いたりはしなかったですが、matsuuさんのazure-isucon-templatesの一つをazureにdeployしてみて、なるほどazureはこういう感じかというのを確認したりはしていました。
当日
10:00
はじまっておもむろにazureにdeployしたところ
テンプレート デプロイ 'Microsoft.Template' は、検証プロシージャによって無効と判断されました。追跡 ID は 'a080b1d6-56fc-47d7-9228-9de96209bd0e' です。詳細については、内部エラーを参照してください。使用方法の詳細については、https://aka.ms/arm-deploy を参照してください。 (コード: InvalidTemplateDeployment)
というエラーがでてしばらく苦しめられる。もしやとおもい検証用にdeployしていた過去問のリソースを削除したら解消。
ISUCON、無料枠の制限とかはまるの嫌なので速攻課金解放した
— fujiwara (@fujiwara) September 11, 2016
fujiwaraさんのこのtweetはもちろん見ていたので、事前に従量課金サブスクリプションを作っていたんですが、今確認したら従量課金なのに無料試用プランであることには変わりがないようで、これどうやって解放するのかわからん。さようならazureという気分です。
deploy完了後、初期状態でPerlで動いていることを確認し、そのまま行くことに。
その後1時間ほどは
- 初回ベンチ実行
- コードのローカルへの転送とgitへの展開
- nginxアクセスログを解析用に修正
- カーネルパラメーターやapt-get, cpanfileの秘伝のタレの投入
- コードの解読
- プロファイリングするまでもない明らかにボトルネックになるポイントをさくっと修正
などをやる。プロファイリングするまでもない明らかにボトルネックになるポイントの修正は具体的には
- ON DUPLICATE KEY UPDATEの無駄なデータの二重転送排除
- author_id = ?, keyword = ?, description = ?, updated_at = NOW() - ], ($user_id, $keyword, $description) x 2); + author_id = VALUES(author_id), keyword = VALUES(keyword), description = VALUES(description), updated_at = NOW() + ], $user_id, $keyword, $description);
- is_spam_contentsをtitle/bodyでひとまとめに
- isupam, isutarへの接続をkeepalive
といったあたり。このへんをやって11:30ごろ5262点で暫定2位の状態で最初の作戦会議の開催。
11:30
スコア: 5262
第一回作戦会議。アクセスログの解析はできていて、静的ファイル配信とトップがとにかく遅いというのを確認。
- cssのnginx serve
- isutarをisudaに吸収
- gzip_static
をまずはやりましょうとなる。キーワードリンク作成のhtmlifyが本丸でしょうという話はしたけどこの時点でこれについての具体的な解決策はなし。
12:07
isutarのisudaへの吸収完了。
スコア: 5262->5392
が、スコア上昇は誤差の範囲。既にkeepaliveはしていたのでこの時点では意味のない施策だったんだと思われ。ただし状況が進んでハイトラフィックな状態になると効いてくると思うので問題なし。
12:09
isudaのworker数を20にしてみるとスコアが倍増
スコア: 5392->11090
12:14
static fileのnginx serve
スコア: 11090->10902
うーん、誤差の範囲。
このあとmysqlのindex作成など細かい施策をしばらく繰り返すがたいしたスコア上昇には繋がらなくなってきたため、本丸のhtmlifyの改修に着手。
14:04
スコア: 11090->25048
トップページ表示のときに正規表現の作成がエントリごとに行われていたのを1回に集約
16:17
正規表現とキーワードリストをmemcachedにキャッシュ
スコア: 25048->61473
htmlifyの最適化は2時間以上ずーっと取り組んで着実にスコアはあがっていったしずっとボードの5-6位以内につけてたけどこのころすでに20万点オーバーのチームが現れており、このままじゃ駄目だ…と焦りはじめる。
なにか違うアプローチでブレークスルーをおこさないと勝てない、ということでhtmlごとキャッシュの戦略を実施する方向に転換。
16:59
PlackのsessionをPlack::Middleware::Session::Simpleに置き換え。
Plack::Middleware::Session::Simple なにがすごいかというと、必要の無い時にSet-Cookieしないところです
— masahiro nagano (@kazeburo) September 18, 2016
logoutの処理を
- $c->env->{'psgix.session'} = {};
+ $c->env->{'psgix.session.options'} = {expire => 1};
にしないとセッションがちゃんと切れずにベンチがfailするのにしばらくはまるが解消。
スコア: 61473->67663
キャッシュするための準備でしかないが、スコアがあがり期待が高まる。
17:03
nginxで$cookie_isuda_sessionがない時だけ
proxy_cache_valid 200 1;
をするようにする。
スコア: 67663->228217
きたー。
で、しばらくもうちょっとスコアあげられないか試したけど誤差の範囲でしか変わりがなかったので17:30ごろにはあとは再起動検証をして終わりにしましょう、となり再起動…
17:38
再起動後1回目
スコア: 18万点台(正確なのはとっておらず)
ん、ちょっとおちたなぁ、mysqlのウォームアップ的なあれだろうか、ともう一度実行することに。
スコア: 30435
え?なんで?何がおきたの?
まったく原因もわからず混乱する一同。そして祈りながらもう一度ベンチマーク実行するも、また数万点台のスコアを叩き出す。
残り時間15分。終わった。俺たちの夏は終わってしまったんやー。
と、泣きそうになりながらもう一度再起動をしてみる…。
17:50
再起動2回目
スコア: 19万点台(正確なのはとっておらず)
よし!なんでかわかんないけど命拾いした!ベストスコアからはおちてるけどこれは予選突破できる数値でしょう。
もうやめよう…と思ったけど、「もう一度走らせてみましょう」というチームメンバー。まじか。止める間もなくエンキューされる。
スコア: 223103 (17:54:14)
なんとその日のベストスコアを更新。そのままフィニッシュ。
感想
最後のはなんだったのかいまだに分からず。終了後にidobataで疑問を呈したりもしたのですが、1秒間のキャッシュというきわどい戦略だったので減点によるブレが大きかったのではないかという推察で終わっています。
エンキューガチャ的なことはなかったと信じたいけど、ちょっとだけもやっとしているので、ベンチの再現環境が提供されたら、いろいろと試してみたいです。
うちがhtmlごと1秒キャッシュというきわどい戦略だったのに対し、他の通過者の感想エントリーを見て回るとhtmlifyの最適化やプリレンダとその効率的なinvalidationなど自分にはできてないことがたくさんあって勉強になるし、これらをちゃんとできるようにならないと本戦は無理だろうなという感じで、2位通過なのにだいぶ厳しい気持ちになっております。
何はともあれ、再びヒカリエでの本戦に参加できることは本当に本当にうれしいです。
songmuさんをはじめ出題者のみなさん、運営者のみなさん、お疲れ様でした。本戦もよろしくお願いいたします。
今度こそ優勝するぞ!
#isucon 5 予選、惨敗でした
- 2015/9/28 月曜日 15:21:37
- ISUCON
毎年でているISUCONに今年も山形組として参加してきました。
今年もオンライン予選があり、9/26(土)の一日目に参加し結果は最高スコアが3000を少し超えるぐらいで惨敗でした。
簡単に何をしたのかをまとめると
事前作戦会議
チーム数多いしボーダーあがって厳しいことになるだろうしトップ狙うつもりでやらないとだろうなとは思ってます
イチかバチかで飛び道具でも使って普通じゃないことをやらないと勝てないと思い込み
kazeburoさんのこの時のエントリなどを読み込み脳内素振りを繰り返す。
当日
11:00
動作確認、コードリーディング
11:30
apt-get update;apt-get dist-upgrade;apt-get install xxx,xxx,xxx & reboot
diskがroの罠にはまる。解決策はわからず、instance作り直し
12:30
第一回作戦会議
今回もインメモリDBでいけそう
という作戦決定…。
mysqlのデータ量がぎりぎりメモリに載せられそうだしこれはインメモリDB組に対する挑戦状や、とか思ってしまいました…。
ちな、/var/lib/mysql/isucon5q/データ量が2.4Gでメモリが3.6G
12:30-15:00
perlにentriesもcommentsものせようとする。が、ある一定の量をのせるとまったく処理がすすまなくなる。おそらくmysqldが確保するページキャッシュとの食い合い。mysqlテーブル側をROW_FORMAT=COMPRESSEDにしたりbuffer_poolを減らしたり増やしたり、Perl側のデータの持ち方を効率化したりいろいろ試すも最後まで実行できず。これはLLなPerlじゃ無理じゃね…と15時ちょうどに断念。(後日富豪インスタンスサーバーで試し、全部読み込んだらPerlのプロセスのメモリが4G超えました!!)
15:00
第二回作戦会議
王道チューニングで1から再開しましょう
16:30
普通のクエリのチューニングを進めていくものの、上位陣が1万を超えるようになってきて焦り
もうだめぽ…こんなふつうのチューニングじゃ勝てない…
ということで、htmlのキャッシュ生成をやってそれを返すとこまでやらないと駄目だと思い込み、その作業を進め始める。
17:40
userデータ5000件のindex.htmlの用意が終わり、それをキャッシュ更新/参照する仕組みでスコア1200ぐらい
18:30
POST時にキャッシュ更新してて3秒にまにあわないから途中でやめてあとはinvalidateだけしていたのをなんとかしないと…そもそもindexの作成のコストがまだクエリチューニングが終わってなくて高すぎる、でも時間ない、ということでPOST時にキャッシュ更新はやめてinvalidateだけするようにしたらスコア3000ちょっと超え、その後悪あがきで/friendsのクエリチューニングなどを始めるもそのままフィニッシュ
感想
飛び道具(今回の場合インメモリDB)の使いみちをきちんと判断できるようになるべきだったなというのが最大の反省点です。
GOで本文データの持ち方を工夫しながら実施して予選突破した方もいたようですしもうちょっとやり方はあったなぁというのもあります。
ISUCON、初期スコアの100倍、200倍にしないと勝てないみたいなのが通説としてあって、だからそれをやってることってめちゃくちゃすごいことなんだと思いがちなんだけど、初期のコードは本当にクソなので、それの100倍でも普通ぐらいのレベルだという学びもありました。後半も、王道といいつつhtmlキャッシュ作成というキテレツなアイデアに執着しており、そんなことは後にしてまずはシンプルにクエリチューニングを進めるべきだし、結局キャッシュ更新速度のためにもそれは必要だった。
毎回本戦に参加していたのもあって思った以上に悔しい気持ちで、夜どうしても寝れなくて昨夜、まだベンチマークもないのに一人反省会で時間があったらやれた後半のチューニングを進めたりしました。githubにあげてます。基本的にほとんどのページでhtmlをそのまま帰すだけの構成になってます。たぶんバグがまだあるけど通ればトップチームに近いかそれ以上の数値がでるんじゃないかなぁ…。
いろいろやれることは多くて非常に面白い問題ではありました。
本戦にいけなくて本当に悔しいですが、来年も、、、あるのかな、あればもちろん参加したいです。
今回も出題チームの皆様は本当に大変そうで、しかし見事にISUCONの予選を成立させており、素晴らしいとしか言いようがないです。本当に感謝です。
あわせて、主催・共催のLINE、Treasure Data、テコラス、Googleの皆様、ありがとうございました。
- about
- カテゴリー
- 最近の投稿
-
- YAPC::Kyoto 2023参加してきました
- #isucon12 参戦記録
- #isucon10 予選惨敗してきました
- #isucon9 参戦記録
- #isucon 8 本戦10位で負けてきました
- #isucon 8 予選15位で通過しました
- #isucon 7 予選敗退しました
- #isucon 6 本戦10位で負けてきました
- #isucon 6 予選二位で通過しました
- #isucon 5 予選、惨敗でした
- YAPC::Asia Tokyo 2015に参加してきました
- #isucon 4 本選10位で惨敗でした
- #isucon 4 予選参加してきました
- #isucon 負けてきました
- #isucon 3 予選総合3位でした
- #ISUCON2 で特別賞を頂いて来ました
- YAPC::Asia Tokyo 2012に参加してきました
- YAPC::Asia Tokyo 2011に参加してきました
- ISUCONに参加してきました
- DBD::mysql 4.020がリリースされました
 ブックマーク
ブックマーク
- 検索
- フィード
- メタ情報